MySql简介
MySql逻辑架构

服务层:为客户端做连接处理,授权和安全认证相关工作
核心层:查询解析,分析,优化SQL语句,缓存结果等等
存储引擎层:存储和提取数据(索引使用)及事务的处理
存储引擎
InnoDb
特点:MySQL5.7之前的版本不支持全文索引,5.7及以后的支持
支持行级锁,锁粒度小
支持ACID(事务完整性和异质性)
独有的聚簇索引主键设计方式,可大发提升并发读写性能
支持外键,支持崩溃数据的自我修复
注意问题
a) 所有InnoDB数据表都创建一个和业务无关的自增数字型作为主键,对保证性能很有帮助;
b) 杜绝使用text/blob,确实需要使用的,尽可能拆分出去成一个独立的表;
c) 时间建议使用 TIMESTAMP 类型存储;
d) IPV4 地址建议用 INT UNSIGNED 类型存储;
e) 性别等非是即非的逻辑,建议采用 TINYINT 存储,而不是 CHAR(1);bool
f) 存储较长文本内容时,建议采用JSON/BSON格式存储;
MyIsam
特点:支持全文索引,
能够对整张表进行加锁,不支持行锁,及锁粒度较大。
缺点:不支持事物,及没有rollback功能。
应用:日志系统,读表的操作,没有事物第并发的网站
隔离级别
Read Uncommitted(读取未提交内容)
在该隔离级别,所有事务都可以看到其他未提交事务的执行结果。本隔离级别很少用于实际应用,因为它的性能也不比其他级别好多少。读取未提交的数据,也被称之为脏读(Dirty Read)。
注意:读取未提交内容会出现赃读
Read Committed(读取提交内容)
这是大多数数据库系统的默认隔离级别(但不是MySQL默认的)。它满足了隔离的简单定义:一个事务只能看见已经提交事务所做的改变。这种隔离级别 也支持所谓的不可重复读(Nonrepeatable Read),因为同一事务的其他实例在该实例处理其间可能会有新的commit,所以同一select可能返回不同结果。
Repeatable Read(可重读)
这是MySQL的默认事务隔离级别,它确保同一事务的多个实例在并发读取数据时,会看到同样的数据行。不过理论上,这会导致另一个棘手的问题:幻读 (Phantom Read)。简单的说,幻读指当用户读取某一范围的数据行时,另一个事务又在该范围内插入了新行,当用户再读取该范围的数据行时,会发现有新的“幻影” 行。InnoDB和Falcon存储引擎通过多版本并发控制(MVCC,Multiversion Concurrency Control)机制解决了该问题。
注意:可重读会出现幻读的情况
Serializable(可串行化)
这是最高的隔离级别,它通过强制事务排序,使之不可能相互冲突,从而解决幻读问题。简言之,它是在每个读的数据行上加上共享锁。在这个级别,可能导致大量的超时现象和锁竞争。
索引实现
目前大部分数据库系统及文件系统都采用B-Tree或其变种B+Tree作为索引结构
B-Tree
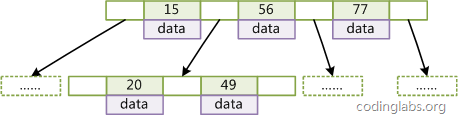
B+Tree
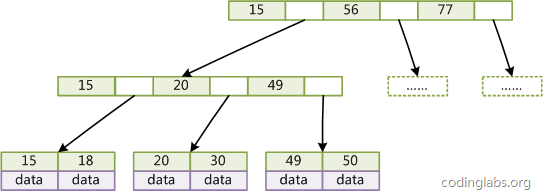
带有顺序访问指针的B+Tree
一般在数据库系统或文件系统中使用的B+Tree结构都在经典B+Tree的基础上进行了优化,增加了顺序访问指针。
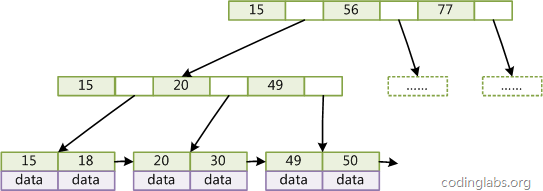
如图所示,在B+Tree的每个叶子节点增加一个指向相邻叶子节点的指针,就形成了带有顺序访问指针的B+Tree。做这个优化的目的是为了提高区间访问的性能,例如图4中如果要查询key为从18到49的所有数据记录,当找到18后,只需顺着节点和指针顺序遍历就可以一次性访问到所有数据节点,极大提到了区间查询效率。
InnoDB索引实现
虽然InnoDB也使用B+Tree作为索引结构,但具体实现方式却与MyISAM截然不同。
第一个重大区别是InnoDB的数据文件本身就是索引文件。从上文知道,MyISAM索引文件和数据文件是分离的,索引文件仅保存数据记录的地址。而在InnoDB中,表数据文件本身就是按B+Tree组织的一个索引结构,这棵树的叶节点data域保存了完整的数据记录。这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引。
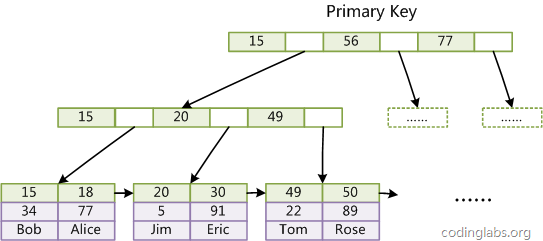
是InnoDB主索引(同时也是数据文件)的示意图,可以看到叶节点包含了完整的数据记录。这种索引叫做聚集索引。因为InnoDB的数据文件本身要按主键聚集,所以InnoDB要求表必须有主键(MyISAM可以没有),如果没有显式指定,则MySQL系统会自动选择一个可以唯一标识数据记录的列作为主键,如果不存在这种列,则MySQL自动为InnoDB表生成一个隐含字段作为主键,这个字段长度为6个字节,类型为长整形。
第二个与MyISAM索引的不同是InnoDB的辅助索引data域存储相应记录主键的值而不是地址。换句话说,InnoDB的所有辅助索引都引用主键作为data域。例如,图11为定义在Col3上的一个辅助索引:
图11
这里以英文字符的ASCII码作为比较准则。聚集索引这种实现方式使得按主键的搜索十分高效,但是辅助索引搜索需要检索两遍索引:首先检索辅助索引获得主键,然后用主键到主索引中检索获得记录。
事务
MVCC实现
MVCC是通过在每行记录后面保存两个隐藏的列来实现的。这两个列,一个保存了行的创建时间,一个保存行的过期时间(或删除时间)。当然存储的并不是实际的时间值,而是系统版本号(system version number)。每开始一个新的事务,系统版本号都会自动递增。事务开始时刻的系统版本号会作为事务的版本号,用来和查询到的每行记录的版本号进行比较。
下面看一下在REPEATABLE READ隔离级别下,MVCC具体是如何操作的。
SELECT
InnoDB会根据以下两个条件检查每行记录:
- InnoDB只查找版本早于当前事务版本的数据行(也就是,行的系统版本号小于或等于事务的系统版本号),这样可以确保事务读取的行,要么是在事务开始前已经存在的,要么是事务自身插入或者修改过的。
- 行的删除版本要么未定义,要么大于当前事务版本号。这可以确保事务读取到的行,在事务开始之前未被删除。
只有符合上述两个条件的记录,才能返回作为查询结果
INSERT
InnoDB为新插入的每一行保存当前系统版本号作为行版本号。
DELETE
InnoDB为删除的每一行保存当前系统版本号作为行删除标识。
UPDATE
InnoDB为插入一行新记录,保存当前系统版本号作为行版本号,同时保存当前系统版本号到原来的行作为行删除标识。
保存这两个额外系统版本号,使大多数读操作都可以不用加锁。这样设计使得读数据操作很简单,性能很好,并且也能保证只会读取到符合标准的行,不足之处是每行记录都需要额外的存储空间,需要做更多的行检查工作,以及一些额外的维护工作
大部分内容摘自:


